Structured Data Extraction from Health Insurance Documents
Objective of the project was to automate extraction of structured data relating to Corporate Health Insurance Coverage Documents. Incoming documents, in PDF and Word documents, containing a mix of structured and unstructured content in the form of paragraphs, Tables and Forms. These capture the various terms and conditions of a corporate Health Benefit Plan. Extracting all the relevant terms from different document sources and filling the information into a complete, harmonized structured data template is a time consuming task performed by human operators who are domain experts. Goal of the engagement was to automate this task using Natural Language Processing (NLP) techniques with a high level of accuracy and completeness.
NLP to automate Structured Data extraction
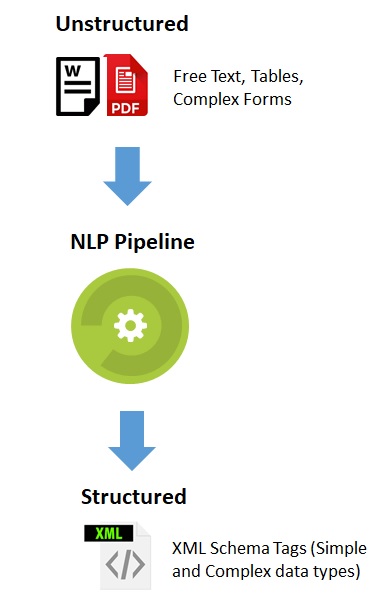
We deployed advanced NLP techniques to automate the task of transforming unstructured data into structured data with high level of accuracy and completeness. The incoming PDF/Word documents have paragraphs of text as well as certain structured content such as tables and forms. The tables and forms have no fixed structure and the relevant information needs to be extracted. Further, the forms have complex control elements such as check boxes, radio buttons and Yes/No questions.
Targeted structured data is an XML schema having various types of datatypes including complex datatypes such as Tables, Boolean fields and Enumerated fields. Semantically correct information needs to extracted from incoming documents and the targeted XML schema populated. Also, the solution was expected to be extensible to support future variations in input and the targeted structured data.
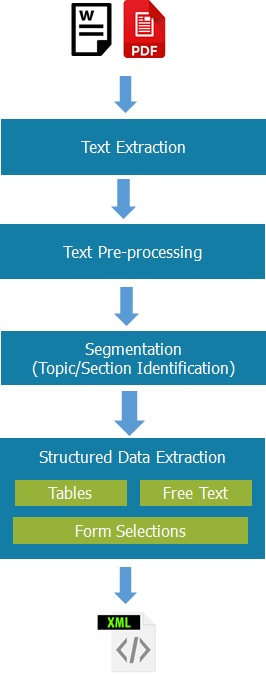
NLP Pipeline
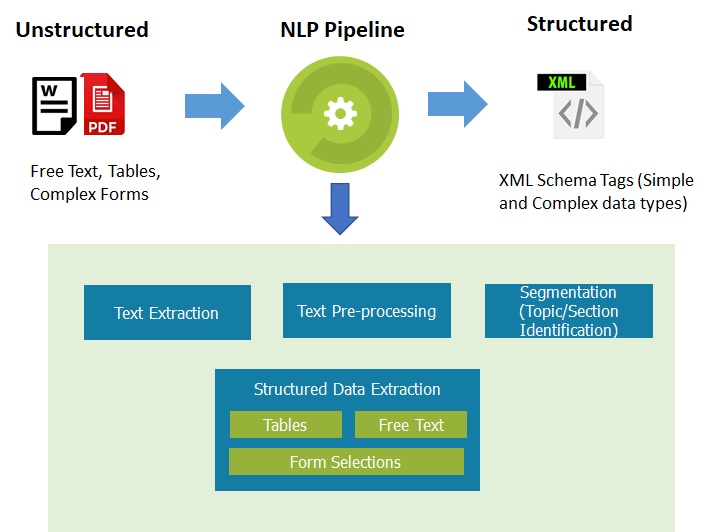
As part of the engagement, our AI/ML team developed a customized NLP process pipeline for the problem. As shown in the Exhibit, the Pipeline consisted of the following key stages:
- Text Extraction : We extract all Text from PDF/Word along with detecting relevant Headings, Tables, Forms, Selections (Yes/No, Check boxes, Radio-buttons etc.). We also extract text from Images embedded in the documents. We evaluated multiple Cloud based text extraction APIs and several open-source text extraction libraries with different configurations. A combination of available open source Text extraction with certain customizations was chosen for Text Extraction purpose.
- Text Pre-processing : We prepare the extracted text into a form that is predictable and analyzable. This includes techniques such as Lower case conversion, Remove stop words, Stemming/Lemmatizing, Removing punctuation/Special Characters and Normalization.
- Text Segmentation : We segment the text into independently analyzable sections. Extracted headings in the unstructured text are matched with with XML Schema Tags in the Structured Data Format. Different strategies are adopted for dealing with content of different type. For example, if the ingested document has Table of Contents, the Content topics become section heading and Text between topics belongs to a section. Further, if the ingested document does not have well defined headings, we prepare a list of expected key words corresponding to each section and classify each paragraph in ingested text based on derived keywords and expected keywords.
- Structured Data Extraction from Segments : Finally, we extract the structured data elements from the derived Segments and populate structured Data in the defined XML Schema. Mix of text matching techniques (such as similarity functions, word embeddings) are used to match the sentences with the tags in the structured data.

Working solution in weeks
By making best use of available NLP tools and techniques and applying with certain customizations to the Customer's context, SenSight team was able to develop a working NLP pipeline in few weeks instead of months. We demonstrated the power and extensability of our chosen approach, wherein each of the Stage could be independently developed and improved further in production stage.
Case Studies
Browse through some of our recent work in the domains of IoT, AI/ML and Cloud.
- All
- IoT Device
- AI and ML
- Cloud and Big Data
- Web and Mobile App